 Department of Psychology
Department of PsychologyFacial animation is a research tool in the Speech Perception and Production Laboratory. Animation allows us to have experimental control of the dynamics of facial motion and gesture cues that are critical to the visual perception of speech and emotion. In recent years we have worked on three types of animation:
-
Direct Motion Capture Animation Approach: facial animation that is controlled directly by kinematic data from motion capture of the head, face and upper body.
-
Principal Components Approach: the principal components of facial deformation were driven by a small set of motion capture data.
-
Physical Model Approach: a physical model of the face that includes the biomechanics of the skin and the physiological characteristics of the facial musculature was driven by recorded facial muscle EMG signals.
1. Direct Motion Capture Animation Approach:
Facial animation that is controlled directly by kinematic data from motion capture of the head, face and upper body. In this approach to facial animation, we try to record the natural visual speech information in as much detail as we can. We use a multi-camera Vicon system with many small passive markers placed on the face. One typical marker map is shown below.
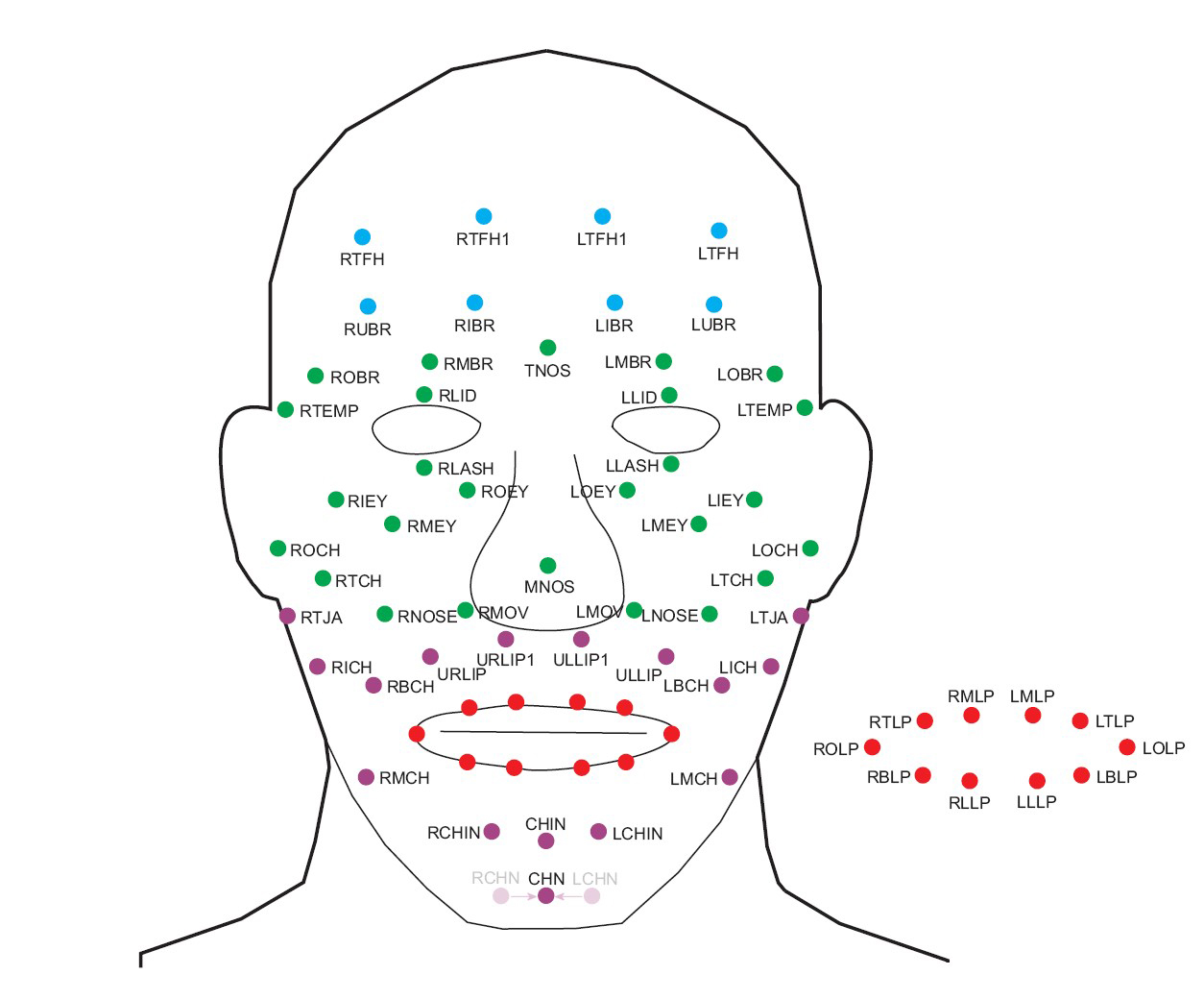
The 3D motion from these markers drive a talking head implemented in Maya. The underlying mesh is deformed by kinematic data from the motion capture and synchronized with recorded voice signals.

The animation is then rendered with a surface texture either in black and white or in colour.

An animation of the part of a motion capture session is shown below.
2. Principal Components Approach:
the principal components of facial deformation were driven by a small set of motion capture data. In this approach created by our colleague Takaaki Kuratate, a facial mesh is constructed with a small set of principal components of deformation based on a set of 3D scans of the face producing the five Japanese vowels and three non-speech postures. The figure below shows examples of these scans.

3D kinematic data from a small set of markers (<20) drives this animation based on a linear estimator relating the marker locations to each of the adapted face meshes.
3. Physical Model Approach:
A physical model of the face that includes the biomechanics of the skin and the physiological characteristics of the facial musculature was driven by recorded facial muscle EMG signals. Our goal, in this type of facial animation, is to make a facial model which could be used in both speech perception and production research. In driving a realistic facial model, we learn about the neural control of speech production and how neural signals interact with the biomechanical and physiological characteristics of the articulators and the vocal tract. In addition, we make possible the systematic manipulation of physical parameters to study their effect on speech perception.
Our facial model is an extension of previous works on muscle-based models of facial animation (Lee, Terzopoulos, and Waters 1993, 1995; Parke and Waters, 1996; Terzopoulos and Waters, 1993; Waters and Terzopoulos, 1991, 1992). The modeled face consists of a deformable multi-layered mesh, with the following generic geometry: the nodes in the mesh are point masses, and are connected by spring and damping elements (i.e., each segment connecting nodes in the mesh consists of a spring and a damper in a parallel configuration). The nodes are arranged in three layers representing the structure of facial tissues. The top layer represents the epidermis, the middle layer represents the fascia, and the bottom layer represents the skull surface. The elements between the top and middle layers represent the dermal-fatty tissues, and elements between the middle and bottom layer represent the muscle. The skull nodes are fixed in the three-dimensional space. The fascia nodes are connected to the skull layer except in the region around the upper and lower lips and the cheeks The mesh is driven by modeling the activation and motion of several facial muscles in various facial expressions.
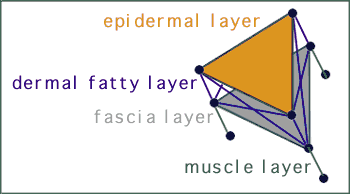
The figure (below) shows the full face mesh. In this figure we have individualized the shape of the mesh by adapting it to a subject's morphology using data from a Cyberware scanner. This is a 3-D laser rangefinder which provides a range map that is used to reproduce the subject's morphology and a texture map (shown below) that is used to simulate the subject's skin quality.

The red lines on the face mesh represent the lines of action of the modeled facial muscles. The lines of action, origins, insertions, and physiological cross-sectional areas are based on the anatomy literature and our measures of muscle geometry in cadavers. Our muscle model is a variant of the standard Hill model and includes dependence of force on muscle length and velocity.
At present, we can drive the model in two ways:
-
by simulating the activation of several facial muscles during various facial gestures or
-
by using processed electromyographic (EMG) recordings from a subject's actual facial muscles.
In the animation below you can watch the face model when it is driven by EMG recordings from the muscles around the mouth. The speaker is repeating the nonsense utterance /upae/. This animation of the lower face movements was produced using only the EMG recordings and thus several seconds of realistic animation were produced from previously recorded muscle activity.