Donald R. Forsdyke and Sheldon J. Bell
Applied Bioinformatics (2004) 3, 3-8
Copying of this article, including placing at another website, requires the written permission of Open Mind Journals, the copyright owner.
[In the final version the publisher required that much of the text of figure legends be incorporated in the main text. However, in the authors opinion, the present text is clearer.]
Keywords: base composition; Chargaff; purine-loading; secondary structure; second parity rule; stem-loops; Szybalski; thermophiles; transcription direction
![]()
Transcription direction rule violates parity rule
Genomic GC% is not increased in thermophiles
Ribosomal RNA is not specifically purine-loaded
Second parity rule is violated more in exons
Oligonucleotide parity is primary
![]()
| Abstract:
DNA base compositions were determined chemically long before sequencing technologies permitted direct counting of bases. Some recent observations made using modern sequencing technologies could have been deduced by application of elementary principles to early chemical observations. This paper draws attention to the fact that the potential for significant stem-loop structure is a general property of single stranded DNA (genic and non-genic), and hence for any corresponding transcripts, whether they function by virtue of their structure (e.g. rRNA) or as mRNA. Furthermore, there is Chargaff's second parity rule: in single strands the percentage of purines approximately equals the percentage of pyrimidines). Since, in stems, purines match pyrimidines, Szybalski's rule that transcripts violate the second parity rule in favour of purines, must apply to loops. Since purine-loading occurs in both mesophilic and thermophilic species, genes with transcripts that need stable secondary structures for functioning at high temperatures must achieve this by selectively increasing the GC percentage (GC%) of stems, while retaining purine-loading of loops. Arguments that purine-loading is specific for the loops of RNA-synonymous strands of genes whose transcripts function by virtue of their secondary structure (i.e. rRNAs, not mRNAs) need to take into account, as controls, the loop regions of mRNA-synonymous strands. Entire genes, or entire genomes where gene orientation is not considered, are not appropriate controls. |
![]()
In addition to his widely recognized first parity rule (A/T and G/C ratios are close to one in duplex DNA), Chargaff noted other regularities in base composition (GC% rule, cluster rule, second parity rule), and Szybalski related base composition to transcription direction (reviewed in Forsdyke and Mortimer 2000 and in Forsdyke 2001). We show here that, despite a rich literature, bioinformaticists may today be making observations that could have been deduced from first principles. Furthermore, inappropriate comparisons can sometimes lead to incorrect interpretations of data. |
Transcription
direction rule violates parity rule
Strands of DNA duplexes that have the same base sequences as the corresponding transcripts (i.e. RNA-synonymous strands) are generally loaded with clusters of purines (i.e. there are more purines than pyrimidines). This locally violates Chargaff's second parity rule; namely that, for single stranded DNA, %A ≈ %T and %G ≈ %C. The violation was suggested by early work from Chargaff's laboratory on the base composition of total RNA from various species, but his data would then have reflected the compositions of the most abundant RNA form, the ribosomal RNAs (rRNAs; Elson and Chargaff 1955). However, the violation was observed for mRNAs in bacteriophage (Szybalski et al 1966), and has since been found to apply generally, even permitting the identification of DNA open reading frames and their transcription directions (Smithies et al 1981; Saul and Battistutta 1988; Bell and Forsdyke 1999). |
Genomic
GC% is not increased in thermophiles
Another general property of duplex DNA
(genic and
intergenic) is the potential to extrude single strands of DNA that adopt
significant secondary structure (for refs. see Forsdyke 1998; Seffens
and Digby 1999; Katz and Burge 2003; Cohen and Skiena 2003). Since the
stability of such structures mainly depends on base parity in stems, it
follows that local violations of Chargaff's second parity rule (e.g.
purine-loading) must primarily affect loops,
and this has been observed
(Bell
and Forsdyke 1999; Figure 1). Furthermore, genes with RNA products that require stable secondary structure for their function in thermophiles (e.g. rRNA genes), achieve this stability by selectively increasing the stem content of the Watson-Crick base pair that contributes most to stability, namely G and C. Genes with RNA products that do not require such stable secondary structure for their function in thermophiles (e.g. mRNA genes), do not have increased stem content of G and C. These genes achieve whatever stability is necessary at the DNA level by other means, such as association with polyamines and relaxation of supercoiling (for refs. see D'Onofio et al 1999; Bernardi 2000; Forsdyke and Mortimer 2000). Thus, the GC-content of genomic DNA, which reflects that of the encoded mRNAs more than of the encoded rRNAs, is not generally increased in thermophiles (for refs. see Lambros et al 2003). |
|
|
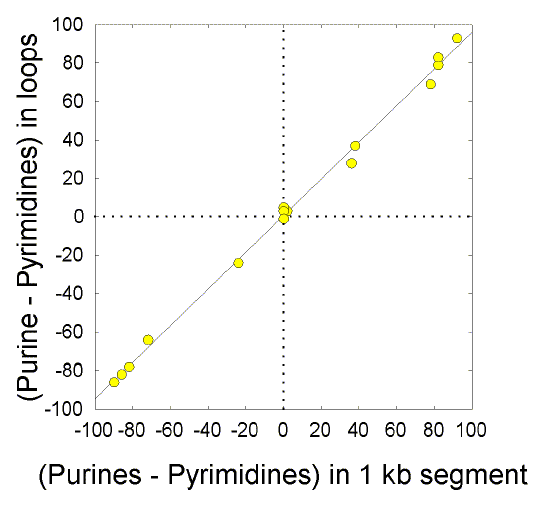
Figure 1 Correlation between Chargaff differences in single strand sequences and the Chargaff differences in the loops of the same sequences when folded into stem-loop secondary structures.Randomly selected 1 kilobase segments from the bacterium E. coli (fragment ECO110K; accession number D10483) were folded into stem-loop structures as described in Forsdyke 1998. Chargaff differences in the "top" strand (i.e. the strand recorded in GenBank) were evaluated both for each full 1 kb sequence, and for the loops and stems in that sequence when folded. For stems, Chargaff differences (differences between total purines and pyrimidines) were approximately zero (data not shown). In general, sequences with a pyrimidine excess (i.e. a negative Chargaff difference in potential loops) correspond to regions where transcription is to the left, and sequences with a purine excess (i.e. a positive Chargaff difference in potential loops) correspond to regions where transcription is to the right. Segments that happen to contain parts of leftward- and rightward-transcribing genes may have zero Chargaff differences. This rather obvious result was reported in the text of Bell and Forsdyke (1999). |
Ribosomal RNA is not specifically purine-loaded
|
In 1985 it was noted that the loops in structural models of Escherichia coli 16S rRNA are purine-loaded (especially adenine; for refs. see Gutell et al 2000). Conservation of 16S rRNA sequences among prokaryotic species suggests that natural selection has favoured (i) purines (A+G), and especially adenine (A), in the single stranded loop regions in all species, and (ii) an increased G+C content of the stem regions in thermophilic species (Wang and Hickey 2002). Little correlation is noted between the nucleotide content of single stranded regions and that of "the whole genome"(Wang and Hickey 2002, p. 2505). This is interpreted as showing that the purine-loading of loop regions is specific for rRNAs. However, a lack of correlation is expected from the fact that the "whole genome" refers to one strand, namely the "top" strand as recorded in databases. Some genes are transcribed to the right and some to the left. In one strand the purine excess characteristic of genes transcribed to the right can be cancelled out by the pyrimidine excess characteristic of genes transcribed to the left (i.e. it is the RNA-synonymous strand that is purine-loaded, so the top strand is only purine-loaded in the case of genes transcribed to the right of the promoter; Forsdyke and Mortimer 2000). If the rRNA genes that are to be compared with whole genome "controls" are preselected as to their transcription direction, then there is purine excess in regions corresponding to loops in rRNA secondary structures in every case. Similar considerations apply to the use "as a control" (Wang and Hickey 2002, p. 2501) of the top strands of entire non-rRNA genes (i.e. mRNAs of genes encoding ribosomal proteins), not the segments of such genes that correspond to loops in mRNA secondary structures. Since selection should operate on the potential for secondary structure of rRNA genes at both genomic (i.e. DNA) and cytosolic (i.e. RNA) levels, whereas mRNA structure is probably largely affected by genome level selection (see below), an appropriately controlled study should be of much interest. It is of note that, although purine-loading of mRNAs is greatly increased in thermophiles (Lao and Forsdyke 2000; Lambros et al 2003), there is little indication of increased purine-loading in 16S rRNA genes in thermophiles (Wang and Hickey 2002). This may relate to the reciprocal relationship between the GC% and the purine-loading (AG%) of a strand. When GC% increases (to support rRNA secondary structure), purine-loading decreases (Lao and Forsdyke, 2000). This is mainly reflected in a selective exchange of C for A (Mortimer and Forsdyke 2003; Lambros et al 2003). In view of this linkage between AG% and GC%, restricting a study to genomes over a limited range of GC% values "in order to reduce the effects of GC bias" (Singer and Hickey 2003, p. 41) could also restrict the range of AG% studied. This could possibly lead to incorrect interpretations of data; for example, that increased AG% in thermophiles is only "a minor contributing factor" (Singer and Hickey 2003, p. 45) to their distinctive amino acid compositions. It seems more likely that the increased AG% is a major contribution factor (Lambros et al 2003; Lobry and Chessel 2003; Paz et al 2004). |
Chargaff's second parity rule for complementary bases (%A ≈ %T and %G ≈ %C), also extends to complementary dinucleotides, trinucleotides, etc. (Ohno 1991; Prabhu 1993; Forsdyke 1995a). In this context, bioinformaticists ponder "why are complementary DNA strands symmetric?" (Baisnee et al 2002, p. 1021). The rule may reflect the general potential of duplex DNA molecules to adopt stem-loop structures (Nussinov 1984), which may have arisen from a selective pressure to enhance recombination potential (Forsdyke 2001). Although some stem-loop potential is often present in the purine-loaded, protein-encoding, regions of genes (i.e. exons), there can be a conflict between the need to both purine-load and protein-encode, and the need to encode stem-loops. Direct measurements of stem-loop potential show that this conflict is less in introns and intergenic DNA, so stem-loop potential is greater in these regions than in exons (Forsdyke 1995b, c). Accordingly, the second parity rule is violated much less in intronic and intergenic DNAs, and these follow Chargaff's second parity rule more closely than exons (Bultrini et al 2003). This is in keeping with evidence that introns are primarily adaptations for sustaining stem-loop potential, so enhancing recombination potential (Forsdyke 1995b; Barrette et al 2001). |
Oligonucleotide parity is primary
In 1995 the questions were posed:
That a distinction might be derived from first principles was not then appreciated. Of course, if "Nature writes" a sequence with parity at the oligonucleotide level, then parity at the single base level is an automatic consequence. However, the converse does not apply (Fig. 2). If evolutionary forces cause a sequence to be "written" with parity at the level of single bases, then parity at the oligonucleotide level does not necessarily follow. Since biological sequences generally show parity at the oligonucleotide level, this suggests that they were initially "written" at that level. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Figure 2 A general method for showing that, if Chargaff's second parity rule applies for complementary mononucleotides (single bases), it does not always extend to complementary dinucleotides, and higher order complementary oligonucleotides, when they are arranged in a circular single strand sequence. For simplicity, first take just two bases, A and T, which pair with each other. Write out a sequence with eight As and eight Ts. Although this sequence (a) is for convenience written as a linear sequence, imagine it is circular with the last base (T) being connected to the first base (A). Does it obey Chargaff's second parity rule? Yes, there are 8 As and 8 Ts. Does the rule extend to complementary dinucleotides? Remembering that the sequence is circular, and that base pairs can overlap, score by writing dinucleotides below the sequence and then counting, as in (b). Note that AA = 7 and its complement TT = 7; AT = 1 and its complement AT = 1; TA = 1 and its complement TA = 1. The similar decomposition into trinucleotides (c) shows AAA = 6 and its complement TTT = 6; AAT = 1 and its complement ATT = 1; TTA = 1 and its complement TAA =1. In this particular sequence there is no numerical distinction between reverse and forward complements in the same strand (Forsdyke 2002). Note that this 16 base sequence could be repeatedly copied and the resulting replicates concatenated to produce one large circular single strand. Whatever the extent of this replication and concatenation, the parity relationship would be retained at the levels both of single bases and of the above oligonucleotides. Thus, if this were the sequence of some organism, it would not be possible to determine whether "Nature" had "written" the sequence at the single base level, with parity at the oligonucleotide level being an automatic consequence, or the converse. Sequence (d), however, also obeys the parity rule (A = 5, T = 5, G = 3, C = 3). Here complementary dinucleotides, trinucleotides, etc., are not necessarily present in equal frequencies. For example, there is no reverse complement (GT) for the two CAs. The trinucleotide TTT is not matched by an AAA. The trinucleotide GGG is not matched by a CCC. Again, the 16 base sequence could be repeatedly copied and the replicates concatenated to produce one large circular single strand. The disparities at the oligonucleotide level would still be present. Parity at the level of single bases does not necessarily imply parity at the oligonucleotide level. Since biological sequences generally show parity at the oligonucleotide level, this suggests that they were initially "written" at that level. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Thus, it is likely that sequences that are of biological origin, and of sufficient length, demonstrate the parity at the single base level because "Nature" initially "wrote" them under the influence of evolutionary forces that required parity at the oligonucleotide level (e.g. to form stems in stem-loop secondary structures). Hence, the most important complement with respect to the second parity rule should be the reverse complement, not the forward complement (Forsdyke 2002). The second parity rule extends to reverse complementary trinucleotides, tetranucleotides, etc., up to a statistical limit set by the length of the sequence examined. Nature "writes" with parity primarily at the oligonucleotide level. By default, there is parity at the mononucleotide level, as has been independently suggested by Baisnee et al (2002) using a different approach. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Table 1 A long artificial sequence (e.g. a concatamer of sequence (d) of Fig. 2) and a long natural sequence, each of the same length and base composition, may differ in the presence (+) or absence (-) of parity at the level of reverse complementary oligonucleotides. The sequences are two members of the set of possible sequences with the same length and base composition. Although improbable, depending on sequence length, the natural sequence on shuffling could give rise to concatamer (d), so that this shuffled version of the natural sequence would violate Chargaff's second parity rule at the oligonucleotide level. Likewise, although improbable, the artificial sequence on shuffling could give rise to itself again, or a subset of sequences like itself, which would again violate Chargaff's second parity rule at the oligonucleotide level. The most probable outcomes, however, are that when bases in these long sequences are randomly shuffled the resulting sequences both have parity at the oligonucleotide level (Forsdyke 1995a). |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| There is more to infer. If a long biological sequence that complies with
Chargaff's second parity rule is shuffled, then there is no change in base
composition in the resulting sequence and the parity rule still applies at the
level of single bases. However, in long shuffled sequences, the parity rule also
usually applies at the oligonucleotide level (Forsdyke
1995a). Inapplicability
of the second parity rule at the oligonucleotide level to shuffled sequences
would be highly improbable, depending on the length of the sequence (Table 1).
Thus, it may be inferred that a given long sequence that obeys Chargaff's second parity rule at the single base level is one of a large set of sequences that could be generated by taking equal quantities of members of each pair of Chargaff bases and shuffling. Actual biological sequences are members of a subset of this larger set, distinguished by the fact that they demonstrate parity at the oligonucleotide level prior to our shuffling of them. This implies the obvious - that "Nature" herself does not usually generate her sequences by random shuffling. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Growing evidence indicates that base composition is under the influence of selection, rather than of mutational bias (D'Onofio et al 1999; Bernardi, 2000; Lynn et al 2002; Lobry and Chessel 2003). The selective value of purine-loading is unknown. One view is that non-canonical purine-purine base pairing between loops stabilizes tertiary intramolecular interactions (Wang and Hickey 2002). Another view is that purine-loading inhibits the intermolecular loop-loop "kissing" interactions that precede formation of double-stranded RNA. The latter may trigger alarms relating to intracellular self/not-self discrimination (Forsdyke and Mortimer 2000; Forsdyke et al 2002). Whatever the explanation, the pioneering studies of Chargaff, Szybalski and their colleagues, should be noted. Chargaff's first parity rule supported the Watson-Crick duplex model for DNA, and his observation of the species specificity of GC% (the GC-rule) may have profound implications for "the mystery of mysteries," the origin of species (Forsdyke 2001). However, the other regularities in base composition that Chargaff observed have received less attention. Arising from Chargaff's cluster rule, the transcription direction rule is becoming generally recognized, and we have suggested that it be named to honour Szybalski's observation that base clustering relates to transcription direction (Forsdyke and Mortimer 2000). Remarkably, many modern observations could have been obtained deductively by application of elementary principles to these early biochemical observations (Figs. 1-2; Table 1; Forsdyke, 2002). |
Acknowledgements
J. R. Lobry and D. Chessel kindly made their paper available prior to publication. M. Zuker facilitated our use of his DNA folding programs. J. Gerlach assisted computer configuration. P. Wills and another reviewer (anonymous) provided valuable advice. Queen's University hosts Forsdyke's web-pages. Here full-text versions of several of the references may be found. |
References
Baisnee P-F, Hampson S, Baldi, P. 2002. Why are complementary DNA strands symmetric? Bioinformatics 18:1021-1033. Barrette IH, McKenna S, Taylor DR, Forsdyke DR. 2001. Introns resolve the conflict between base order-dependent stem-loop potential and the encoding of RNA or protein: further evidence from overlapping genes. Gene 270:181-189. Bell SJ, Forsdyke DR. 1999. Deviations from Chargaff's second parity rule correlate with direction of transcription. J. Theor. Biol. 197:63-76. Bernardi G. 2000. Isochores and the evolutionary genomics of vertebrates. Gene 241:3-17. Bultrini E, Pizzi E, Giudice PD, Frontali C. 2003. Pentamer vocabularies characterizing introns and intron-like intergenic tracts from Caenorhabditis elegans and Drosophila melanogaster. Gene 304:183-192. Cohen B, Skiena S. 2003. Natural selection and algorithmic design of mRNA. J. Comput. Biol. 10:419-432. D'Onofio G, Jabbari K, Musto H, Alvarez-Valin F, Cruveiller S, Bernardi G. 1999. Evolutionary genomics of vertebrates and its implications. Ann. N. Y. Acad. Sci. 870:81-94. Elson D, Chargaff E. 1955. Evidence of common regularities in the composition of pentose nucleic acids. Biochem. Biophys. Acta 17:367-376. Forsdyke DR. 1995a. Relative roles of primary sequence and (G+C)% in determining the hierarchy of frequencies of complementary trinucleotide pairs in DNAs of different species. J. Mol. Evol. 41:573-581. Forsdyke DR. 1995b. A stem-loop "kissing" model for the initiation of recombination and the origin of introns. Mol. Biol. Evol. 12:949-958. Forsdyke DR. 1995c. Conservation of stem-loop potential in introns of snake venom phospholipase A2 genes. Mol. Biol. Evol. 12:1157-1165. Forsdyke DR. 1998. An alternative way of thinking about stem-loops in DNA. J. Theor. Biol. 192:489-504. Forsdyke DR. 2001. The Origin of Species, Revisited. Montreal: McGill-Queen's University Press. Forsdyke DR, Madill CA, Smith, SD. 2002. Immunity as a function of the unicellular state: implications of emerging genomic data. Trends Immunol. 23:575-579. Forsdyke DR. 2002. Symmetry observations in long nucleotide sequences: a commentary on the Discovery Note of Qi and Cuticchia. Bioinformatics 18:215-217. Forsdyke DR, Mortimer JR. 2000. Chargaff's legacy. Gene 261:127-137. Gutell RR, Cannone JJ, Shang Z, Du Y, Serra MJ. 2000. A story: unpaired adenosine bases in ribosomal RNAs. J Mol Biol 304:335-354. Katz L, Burge CB. 2003. Widespread selection for local RNA structure in coding regions of bacterial genes. Genome Res. 13:2042-2051. Lambros RJ, Mortimer JR, Forsdyke DR. 2003. Optimum growth temperature and the base composition of open reading frames in prokaryotes. Extremophiles 7:443-450. Lao PJ, Forsdyke DR. 2000. Thermophilic bacteria strictly obey Szybalski's transcription direction rule and politely purine-load RNAs with both adenine and guanine. Genome Res. 10:228-236. Lobry JR, Chessel D. 2003. Internal correspondence analysis of codon and amino acid usage in thermophilic bacteria. J. Appl. Genet. 44:235-261. Lynn DJ, Singer GAC, Hickey DA. 2002. Synonymous codon usage is subject to selection in thermophilic bacteria. Nucleic Acids Res. 30:4272-4277. Mortimer JR, Forsdyke DR. 2003. Comparison of responses by bacteriophage and bacteria to pressures on the base composition of open reading frames. Appl. Bioinformatics 2:47-62. Nussinov R. 1984. Strong doublet preferences in nucleotide sequences and DNA geometry. J. Mol. Evol. 20:111-119. Ohno S. 1991. The grammatical rule of DNA language: messages in palindromic verses. In Osawa S, Honjo T. eds. Evolution of Life. Berlin: Springer-Verlag, pp. 97-108. Paz A, Mester D, Baca I, Nevo E, Korol A. 2004. Adaptive role of increased frequency of polypurine tracts in mRNA sequences of thermophilic prokaryotes. Proc. Natl. Acad. Sci. USA 101:2951-2956 Prabhu VV. 1993. Symmetry observations in long nucleotide sequences. Nucleic Acids Res. 21:2797-2800. Saul A, Battistutta D. 1988. Codon usage in Plasmodium falciparum. Mol. Biochem. Parasitol. 27:35-42. Seffens W, Digby D. 1999. mRNAs have greater negative folding free energies than shuffled or codon-choice randomized sequences. Nucleic Acids Res. 27:1578-1584. Singer GAC, Hickey DA. 2003. Thermophilic prokaryotes have characteristic patterns of codon usage, amino composition and nucleotide composition. Gene 317:39-74. Smithies O, Engels WR, Devereux JR, Slightom J, Shen S. 1981. Base substitutions, length differences and DNA strand asymmetries in the human Gλ and Aλ fetal globin gene region. Cell 26:345-353. Szybalski W, Kubinski H, Sheldrick P. 1966. Pyrimidine clusters in the transcribing strands of DNA and their possible role in the initiation of RNA synthesis. Cold. Spring Harb. Symp. Quant. Biol. 31:123-127. Wang H-C, Hickey DA. 2002. Evidence for strong selective constraint acting on the nucleotide composition of 16S ribosomal RNA genes. Nucleic Acids Res. 30:2501-2507. |
| For a
commentary on some aspects of this paper see:
D. A. Hickey and G. A. C. Singer (2004) Genomic and proteomic adaptations to growth at high temperature. Genome Biology 5, issue 10, article 117. |
| See End Note 2009 to Forsdyke (2005) for further discussion of Figure 2 showing that, whereas generation of complementary oligonucleotide equifrequency from complementary mononucleotide equifrequency is conditional, the converse is unconditional. Click Here |
![]()
Go to Bioinformatics Index Click Here
Go to Home Page Click Here
![]()
This page was established in 2004, and last edited on 08 Nov 2020, by Donald Forsdyke