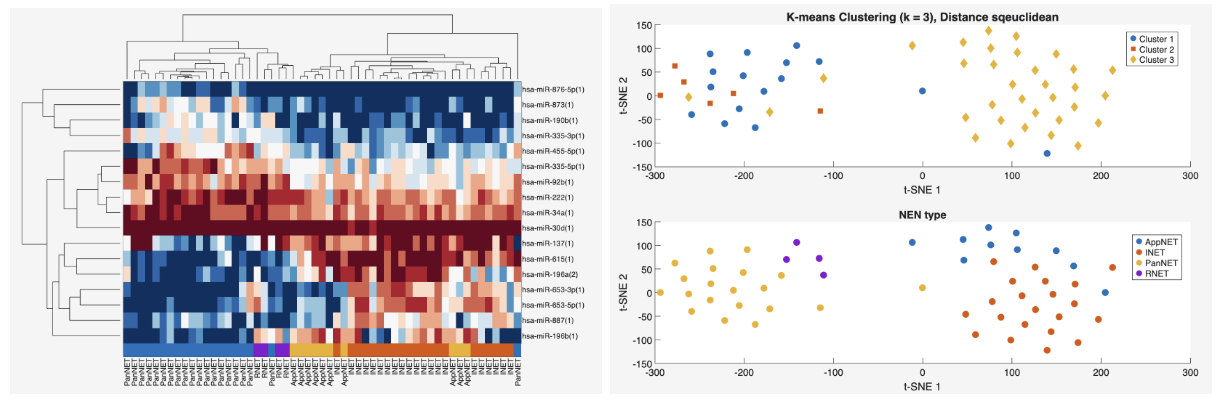
This module provides interactive tools for unsupervised clustering of high-dimensional datasets. Users can explore structure in the data using either hierarchical clustering or k-means clustering, with customizable similarity metrics and visualization options.
Access the .m files through https://github.com/Renwick-Tyryshkin-Lab

Upload data and select sample and feature label
use ' load <datafilename> ' in the command window to establish your file in the input data dropdown.
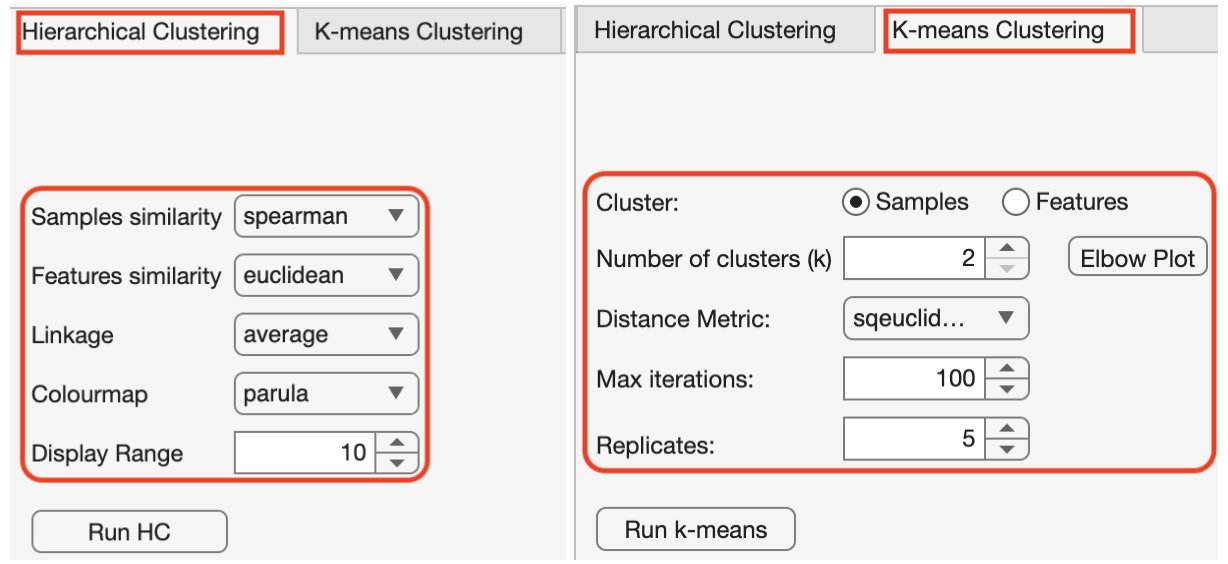
Choose clustering type and details
Select either hierarchical clustering or K-mean clustering.
Within each clustering type, specify relevant parameters.