 Queen's 2015 Nobel Prize in Physics
Queen's 2015 Nobel Prize in Physics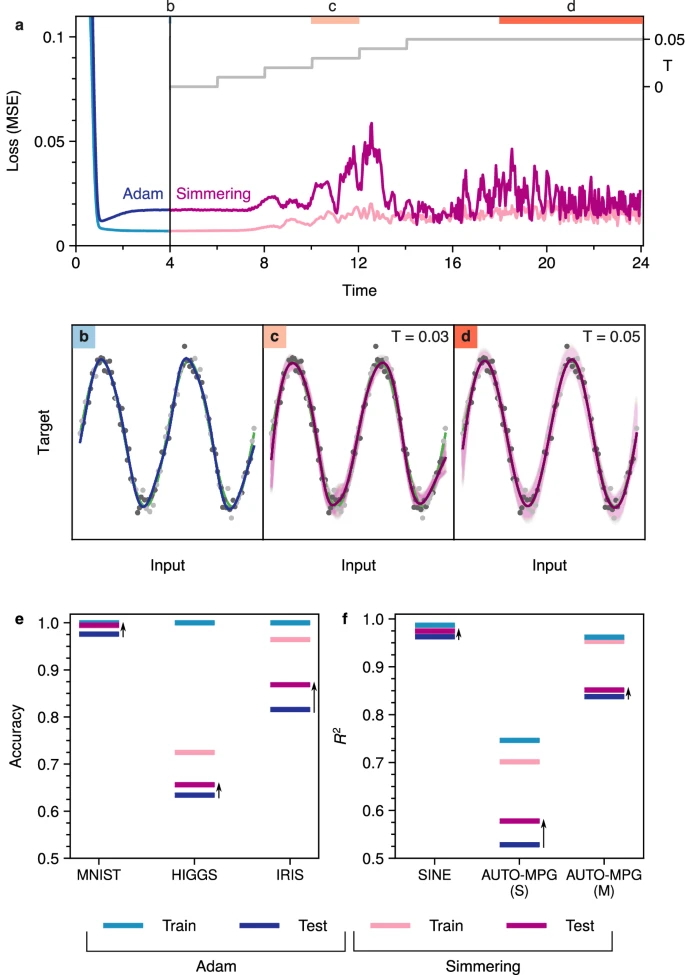
(Click on image to enlarge, caption is included).
Optimization-based training produces discrepancies in performance on training vs. test data (c.f. light blue and dark blue MSE curves, panel (a)) that manifest in discrepancies between model fits and underlying relationships (c.f. dark blue and green curves, respectively, in panel (b)). We apply simmering to retrofit the overfit network by gradually increasing temperature (c.f. gray lines in panel (a)), which reduces overfitting (panel (c)) before producing an ensemble of networks that yield model predictions that are nearly indistinguishable from the underlying data distribution (c.f. dark magenta and green curves, panel (d)). Analogous applications of simmering can be employed to retrofit classification problems (panel (e)) and regression problems (panel (f)). Panel (e) shows prediction accuracy for image classification (MNIST), event classification (HIGGS), and species classification (IRIS). Panel f shows fit quality (squared residual, R2) for regression problems including the sinusoidal fit shown in detail in panels a-d, as well as single (S) and multivariate regression (M) of automotive mileage data (AUTO-MPG). In all cases, simmering reduces the overfitting produced by Adam (indicated by black arrows).
(Photo source: Nature article)
Excerpt from the Queen's Gazette article:
A Queen’s research team [Dr. van Anders, Irina Babayan, Hazhir Aliahmadi] has developed a new way to train AI systems so they focus on the bigger picture instead of specific, optimized data.
Training a neural network can be a bit like preparing a student for an exam. If the student memorizes every practice question and answer, they might score well on a familiar test, but struggle when the questions change. Real learning means understanding bigger ideas. A Queen’s research team says many artificial intelligence (AI) systems have fallen into the memorization trap, and they have developed a new training approach designed to help neural networks learn more effectively.
Full article:
Nature Article
Sufficient is better than optimal for training neural networks
More Research Highlights

Date Published: Mar 20, 2026
Measuring the Mass of the Solar Neighborhood of the Galaxy
Prof. Larry Widrow and his colleagues apply a new method. The research is also highlighted in the Physics Magazine.

Date Published: Dec 19, 2025
Nature Paper on Ising Machine
Publication in prestigious Nature journal.
Date Published: May 19, 2025
Hughes Group and Collaborators publish back-to-back Physical Review Letters
Publications in the exciting fields of Quantum Optics and Ultrastrong Coupling of Light and Matter.